
计算智能导论作业——FCM 聚类的实现
目 录
1 背景知识 1
1.1 FCM 算法原理 1
2 数据集简介 1
2.1 Iris 数据集 1
3 实验环境 1
4 代码实现 2
5 结果分析 4
6 总结 4
A Iris FCM 程序代码 5
1 背景知识
1.1 FCM 算法原理
FCM 算法 (Fuzzy c-Means) 也称为模糊 $C$ 均值算法,是一种基于划分的聚类算法,他的思想就是使得被划分到同一簇的对象之间相似度最大, 而不同簇之间的相似度最小。模糊 $C$ 均值算法是普通 $C$ 均值算法的改进,普通 $C$ 均值算法对于数据的划分是硬性的,而 FCM 则是一种柔性的模糊划分。通过隶属度函数来描述样本属于某个集合的程度, 其自变量范围是所有样本点的所有值,值域范围是 $[0,1]$ ,即 $0 \leq \mu_A(x) \leq 1$。
有了模糊集合的概念, 一个元素属于某个类就不是硬性的, 而是属于某个聚类的隶属度是区间 $[0,1]$ 之间的值,样本属于所有类的隶属度之和应该等于 1,可以表示为
$$
J(U,z_{1},z_{2},\ldots,z_{c}) = \sum_{j = 1}^c J_j = \sum_{j = 1}^c \sum_{i = 1}^m u_{ij}^{\alpha} d_{ij}^2
$$
对输入参量进行求导, 使得目标函数达到最小值的条件: 聚类中心:
$$
z_{i} = \frac{\sum_{i = 1}^m u_{ij}^{\alpha} x_{i}}{\sum_{i = 1}^m u_{ij}^{\alpha}}
$$
隶属度矩阵中的值:
$$
u_{ij} = \frac{1}{\sum_{k = 1}^c \left( \frac{d_{ij}}{d_{ik}} \right)^{\frac{2}{\alpha - 1}}}
$$
该算法的思路即为如下:
Step1: 初始化隶属度矩阵
Step2: 计算聚类中心
Step3: 计算代价函数
Step4: 计算新的隶属度矩阵, 并返回 Step2
2 数据集简介
2.1 Iris 数据集
Iris 数据集是模式识别中最著名的数据集之一。Iris 数据集包含 3 个类, 每个类有 50 个实例, 其中每一类都是指一种鸢尾属植物。有一类是与另外两类是线性可分的, 而另外两类之间是线性不可分的。
3 实验环境
- 系统: Windows 10
- 程序运行环境: Python 3.8
- Python 库: numpy、pandas、matplotlib、sklearn、random
- 开发工具: Spyder、Pycharm
4 代码实现
在代码实现这里, 这里首先创建了一个 FCM 聚类的类, 这个类的初始化部分用于初始化参数, 初始化的参数包括聚类中心与隶属度矩阵, 隶属度矩阵每行之和为 1 , 数据随机设置。随后创建了一个 fit 的函数用于计算聚类中心, 创建了一个 cost 函数计算代价函数, 创建 cal_u 函数更新隶属度矩阵, 随后创建了一个 cal_label 函数计算聚类后的标签, 创建 imshow 函数用于降维可视化, 具体代码如下:
class FuzzyCMeans():
def init__(self, data, c, alpha=2):
self.alpha ( = ) alpha
self.data ( = ) data
self.c ( = c)
self.row, self.col = data.shape
self.matrix ( = ) np.zeros((self.row,self.c))
for i in range(self.row):
for (j) in range(self.c-1):
if np.sum(self.matrix[i, :]) < 1 :
self.matrix[i, j] = random.uniform(0, 1 -
np.sum(self.matrix[i, :]))
self.matrix[i,self.c - 1] = 1 - np.sum(self.matrix[i, :])
self.centers ( = ) np.zeros((self.c,self.col))
def fit(self):
for (j) in range(self.c):
up1 ( = 0)
down1 ( = 0)
for i in range(self.row):
up1 += (self.matrix[i, j] ** self.alpha) * self.data[i]
down1 += self.matrix[i, j] ** self.alpha
self.centers[j] = up1 / down1
def cost(self):
sum ( = 0)
for (j) in range(self.c):
for i in range(self.row):
sum += (self.matrix[i, j] ** self.alpha) *
(np.linalg.norm(self.data[i] - self.centers[j]) ** 2)
return sum
def cal_u(self):
for i in range(self.row):
for (j) in range(self.c):
down2 ( = 0)
for (\mathrm{k}) in range (self.c):
down2 += (np.linalg.norm(self.data[i] - self.centers[j])
/ np.linalg.norm(
self.data[i] - self.centers[k])) ** (2 / (self.alpha
( {-} 1)))
self.matrix (\lbrack i,j\rbrack = 1/\left( \operatorname{down}2 \right))
def cal_label(self):
lab ( = ) np.argmax(self.matrix,axis=1)
return lab
def calcute(self, epochs):
for epoch in range(epochs):
self.fit()
result ( = \operatorname{self} {\cdot} \operatorname{cost}())
print (result)
self.cal_u()
label = self.cal_label()
return label
def imshow(self, label):
tsne ( = TSNE(n_) components ( = 2) ,
learning_rate=100).fit_transform(self.data)
pca ( = ) PCA().fit_transform(self.data)
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.scatter(tsne[:,0],tsne[:,1], c=label)
plt.title(‘t-SNE’)
plt.subplot(122)
plt.scatter(pca[:,0],pca[:,1], c=label)
plt.title(‘PCA’)
plt.colorbar()
plt.show()
然后是主函数部分, 此部分是关于创建出的类的使用, 首先读取数据并创建类的对象, 设置迭代次数为 50 , 然后使用 fcm 聚类方法进行计算得到结果, 然后进行可视化并计算聚类的标准轮廓系数, 代码如下:
if _name == ‘main‘:
(c = 3)
iris ( = ) load_iris()
data ( = ) iris.data
# target = iris.target
(f\mathrm{\ cm} = ) FuzzyCMeans(data, (c = c) )
label ( = f\mathrm{\ cm}) . calcute (epochs ( = 50) ) print(label)
fcm.imshow(label)
(s = ) metrics.silhouette_score(data,label,metric=’euclidean’) print(‘轮廓系数为 ({: .4f}) ‘.format(s))
5 结果分析
经过实验, 可以得到最终结果如下图所示, 其中代价函数最后为 60.5057, 计算得到的
轮廓系数为 0.5495 , 由下图可以看出, 聚类效果很好, 完成了聚类的任务。
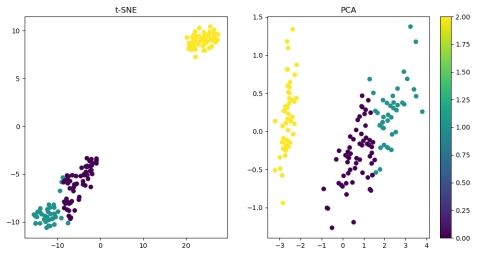
图 1: 结果图
6 总结
本次作业算法相当一部分都已经给出, 因此写的过程中问题不大, 在这次实验中遇到的一个问题是在开始初始化隶属度矩阵的时候, 我将矩阵的所有值都统一为聚类数分之一, 这样导致的后果是随着迭代进行, 聚类中心以及隶属度矩阵都没有发生变化, 后来经过仔细检查才发现问题并进行解决。
在这次实验中, 开始在理解题意方面遇到了很多问题, 后来经过多方询问才明白。这次实验中我通过广泛查询资料了解到了相关的知识, 也认真写代码来完成任务, 这份作业的完成确实比较艰巨, 一份顶多份, 但是我还是有很大的收获, 能力也得到了提升。
A Iris FCM 程序代码
1 | import numpy as np |




