defDBSCAN(dataSet, e, minPts): coreObjs = {} # 初始化核心对象集合 C = {} n = dataSet.shape[0] # 找出所有核心对象,key是核心对象的index,value是ε-邻域中对象的index for i inrange(n): neibor = getNeibor(dataSet[i], dataSet, e) iflen(neibor) >= minPts: coreObjs[i] = neibor oldCoreObjs = coreObjs.copy() k = 0# 初始化聚类簇数 notAccess = list(range(n)) # 初始化未访问样本集合(索引) whilelen(coreObjs) > 0: OldNotAccess = [] OldNotAccess.extend(notAccess) cores = coreObjs.keys() # 随机选取一个核心对象 randNum = random.randint(0, len(cores) - 1) cores = list(cores) core = cores[randNum] queue = [] queue.append(core) notAccess.remove(core) whilelen(queue) > 0: q = queue[0] del queue[0] if q in oldCoreObjs.keys(): delte = [val for val in oldCoreObjs[q] if val in notAccess] # Δ = N(q)∩Γ queue.extend(delte) # 将Δ中的样本加入队列Q notAccess = [val for val in notAccess if val notin delte] # Γ = Γ\Δ k += 1 C[k] = [val for val in OldNotAccess if val notin notAccess] for x in C[k]: if x in coreObjs.keys(): del coreObjs[x] return C
# Data : 2021/5/10 23:10 import numpy as np import pandas as pd import sklearn import random from sklearn import datasets from sklearn.preprocessing import scale from sklearn.manifold import TSNE from sklearn.decomposition import PCA import matplotlib.pyplot as plt from sklearn.metrics import silhouette_score
classKmeans(): def__init__(self,dat,k): data=scale(dat) self.data=data self.row, self.col = data.shape self.k=k self.centers=np.ndarray((k,self.col)) choices=random.choices(range(self.row),k=k) for i inrange(k): self.centers[i,:]=self.data[choices[i],:] deffit(self): count=0 while(count<15): self.labels=np.zeros((self.row)) for i inrange(self.data.shape[0]): dis=[] for j inrange(self.k): dis.append(np.linalg.norm(self.data[i,:]-self.centers[j,:],axis=0)) lab=np.argmin(dis,axis=0) self.labels[i]=lab self.result={} for i inrange(self.k): type=np.where(self.labels==i)[0] self.result[i]=type iflen(type)==0: self.centers[i, :] =0 else: self.centers[i,:]=np.mean(self.data[type,:],axis=0) count+=1 return self.centers, self.result,self.labels
import numpy as np import pandas as pd import sklearn import random from sklearn import datasets from sklearn.preprocessing import scale from sklearn.manifold import TSNE from sklearn.decomposition import PCA import matplotlib.pyplot as plt from PIL import Image import cv2
classKmeans(): def__init__(self,dat,k): data=scale(dat) self.data=data self.row, self.col = data.shape self.k=k self.centers=np.ndarray((k,self.col)) choices=random.choices(range(self.row),k=k) for i inrange(k): self.centers[i,:]=self.data[choices[i],:] deffit(self,counts=15): count=0 while(count<counts): self.labels=np.zeros((self.row)) for i inrange(self.data.shape[0]): dis=[] for j inrange(self.k): dis.append(np.linalg.norm(self.data[i,:]-self.centers[j,:],axis=0)) lab=np.argmin(dis,axis=0) self.labels[i]=lab self.result={} for i inrange(self.k): type=np.where(self.labels==i)[0] self.result[i]=type iflen(type)==0: self.centers[i, :] =0 else: self.centers[i,:]=np.mean(self.data[type,:],axis=0) count+=1
# Data : 2021/5/9 15:16 # 调用科学计算包与绘图包 import numpy as np import random import matplotlib.pyplot as plt import scipy.io as scio import matplotlib.colors as mcolors from sklearn import metrics import sklearn from sklearn.preprocessing import StandardScaler from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
defcalDist(X1, X2): sum = 0 for x1, x2 inzip(X1, X2): sum += (x1 - x2) ** 2 returnsum ** 0.5
defgetNeibor(data, dataSet, e): res = [] for i inrange(dataSet.shape[0]): if calDist(data, dataSet[i]) < e: res.append(i) return res
defDBSCAN(dataSet, e, minPts): coreObjs = {} # 初始化核心对象集合 C = {} n = dataSet.shape[0] # 找出所有核心对象,key是核心对象的index,value是ε-邻域中对象的index for i inrange(n): neibor = getNeibor(dataSet[i], dataSet, e) iflen(neibor) >= minPts: coreObjs[i] = neibor oldCoreObjs = coreObjs.copy() k = 0# 初始化聚类簇数 notAccess = list(range(n)) # 初始化未访问样本集合(索引) whilelen(coreObjs) > 0: OldNotAccess = [] OldNotAccess.extend(notAccess) cores = coreObjs.keys() # 随机选取一个核心对象 randNum = random.randint(0, len(cores) - 1) cores = list(cores) core = cores[randNum] queue = [] queue.append(core) notAccess.remove(core) whilelen(queue) > 0: q = queue[0] del queue[0] if q in oldCoreObjs.keys(): delte = [val for val in oldCoreObjs[q] if val in notAccess] # Δ = N(q)∩Γ queue.extend(delte) # 将Δ中的样本加入队列Q notAccess = [val for val in notAccess if val notin delte] # Γ = Γ\Δ k += 1 C[k] = [val for val in OldNotAccess if val notin notAccess] for x in C[k]: if x in coreObjs.keys(): del coreObjs[x] return C
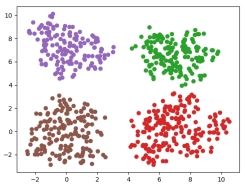
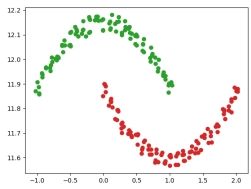
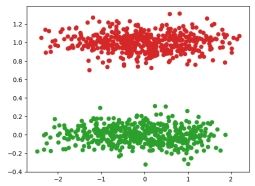
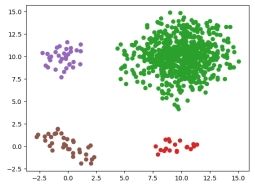
defdraw(C, D): colors = list(mcolors.TABLEAU_COLORS.keys()) predict = np.zeros((D.shape[0], D.shape[1] + 1)) j = 0 keys = C.keys() print(keys) for k in keys: for i in C[k]: predict[j, 0:2] = D[i] predict[j, 2] = k j = j + 1 plt.scatter(D[i, 0], D[i, 1], color=colors[k + 1]) plt.show() return predict