
计算智能导论作业——感知器实现二分类
目 录
1 背景知识 1
1.1 基本定义 1
1.2 感知器的损失函数 1
1.3 感知器的训练 1
2 数据集 2
3 代码实现 2
4 结果展示与分析 4
4.1 数据集一 4
4.2 数据集二 5
4.3 数据集三 5
5 探究 6
6 总结 7
A 程序代码 8
1 背景知识
1.1 基本定义
感知器可以实现简单的布尔运算, 可以拟合任何的线性函数, 任何线性分类或线性问题都可以用感知器来解决, 布尔运算就可以看作是一个二分类问题, 用一条直线将两类分开。感知器无法实现异或运算, 因为异或运算不是线性的, 无法用一条直线将两类分开。
与逻辑斯蒂回归从概率的角度判别不同, 感知机可以理解为从几何的角度上做判断, 即
求得一个分离超平面, 可以将对应输入空间中的实例划分为正负两类。
一个感知器有如下组成部分:
输入权值: 一个感知器可以接收多个输入 $(x_{1},x_{2},\ldots,x_{n} | x_{i} \in \mathbb{R})$, 每个输入上有一个权值 $\omega_{i} \in \mathbb{R}$, 此外还有一个偏置项 $b \in \mathbb{R}$, 就是上图中的 $\omega_{0}$。
激活函数: 感知器的激活函数可以有很多选择, 比如我们可以选择下面这个阶跃函数 $f$ 来作为激活函数:
$$
f(z) = \begin{cases}
1 & \text{if } z > 0 \
0 & \text{otherwise}
\end{cases}
$$输出: 感知器的输出由下面这个公式来计算
$$
y = f(\mathbf{w} \cdot \mathbf{x} + b)
$$
1.2 感知器的损失函数
为了求得感知器的权重参数, 需要确定一个学习策略, 即定义损失函数并将损失函数
极小化。有这样几种选择:
误分类点的总数: 损失函数不是 $w,b$ 的连续可导函数, 不易优化。
误分类点到超平面的总距离: 感知器所采用的损失函数。感知器的损失函数是:
感知器学习问题转化为上式损失函数的最优化问题, 最优化的方法是随机梯度下降法。
当训练数据集线性可分时, 感知器学习算法原始形式是收玫的。
1.3 感知器的训练
感知器的权值和偏置项是利用感知器训练算法得出的, 首先将权重项和偏置项初始化为 0, 然后, 利用下面的感知器规则迭代地修改 $w_{i}$ 和 $b$, 直到训练完成。
$$
w_{i} \leftarrow w_{i} + \Delta w_{i}
$$
$$
b \leftarrow b + \Delta b
$$
其中:
$$
\Delta w_{i} = \eta(t - y)x_{i}
$$
$$
\Delta b = \eta(t - y)
$$
$w_{i}$ 是与输入对应的权重项, $b$ 是偏置项。事实上, 可以把 $b$ 看作是值永远为 1 的输入所对应的权重。$t$ 是训练样本的实际值,一般称之为 label。而 $y$ 是感知器的输出值, 它是根据上面的公式计算得出的。$\eta$ 是一个称为学习速率的常数, 其作用是控制每一步调整权的幅度。
每次从训练数据中取出一个样本的输入向量 $x$, 使用感知器计算其输出 $y$, 再根据上面的规则来调整权重。每处理一个样本就调整一次权重。经过多轮迭代后(即全部的训练数据被反复处理多轮),就可以训练出感知器的权重,使之实现目标函数。
2 数据集
在本次实验中, 选择了三组数据, 第一组是自己生成的 200 个二维的数据, 一共两组, 每组 100 个数据,一组是以 (({-}2, {-} 2)) 为均值,标准差为 1.5 的数据,另一组是以 ((2,2)) 为均值, 标准差为 1.5 的数据, 这两类数据中有一点交叉, 使得数据不能完全线性可分。
第二组数据是读取的自定义的数据, 一共两类, 这两类数据之间有一定的间隔, 是完全
线性可分的。
第三组数据是著名的数据集 Sonar, Sonar 数据集是一个声纳信号分类数据集, 声纳信号从一个金属圆柱体上反弹, 或者从一个大致呈圆柱形的岩石上反弹。每个样本是一个 60 维向量。每个数字表示特定频带内的能量, 范围从 0 到 1 。如果是从一块岩石上反弹, 则样本标签为 “R”, 如果是从一个金属圆柱体上反弹则为 “M”。
3 代码实现
在代码实现中, 这里首先创建了一个感知器类, 首先根据输入数据的维度初始化权重向量以及偏置的值。然后定义类的内置函数, 包括计算以及权值更新函数, 利用权值以及偏置的更新公式进行更新。随后这里定义了一个作图函数, 将数据展示出, 并画出分界面。随后是分别对三个数据集进行读取, 然后定义激活函数为阶跃函数。最后是主函数, 完成感知器的全过程, 并计算出分类后的准确率。具体代码如下:
感知器类的定义函数:
class Perceptron():
def init__(self,input_num,f):
self.input_num=input_num
self.weights=np.ones(input_num)
self.bias=2.0
self.activation=f
def_str__(self):
return f’weight={self.weights},bias={self.bias}’
def predict(self,inputs):
return self.activation(np.dot(inputs, self.weights)+self.bias)
def train(self,inputs,labels,rate=0.1):
for (j) in range (inputs. shape [0]):
output=self.predict(inputs[j])
self.weights=self.weights+rate*(labels[j]-output)inputs[j]
self.bias=self.bias+rate(labels[j]-output)
前两个数据集的作图函数:
def plot_result(perceptron, result):
knew ( = ) -perceptron.weights (\lbrack 0\rbrack/) perceptron.weights [1] bnew ( = ) -perceptron.bias / perceptron.weights [1] (\mathrm{x} = \mathrm{np}) . linspace (({-}5,5))
(y = 1) ambda (x : knew * x + bnew) plt.xlim(-8,8) plt.ylim(-8,8)
plt.plot(x, y(x), ‘b–’)
plt.scatter(data[:, 0], data[:, 1], c=result) plt.title(‘Binary Classification’) plt.show()
对高维度数据集的作图函数:
def imshow(data,result):
tsne ( = ) TSNE(n_components ( = 2) ,learning_rate ( = 100) ). fit_transform(data)
pca ( = PCA()) . fit_transform(data)
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.scatter(tsne[:, 0], tsne[:, 1], c=result)
plt.title(‘t-SNE’)
plt.subplot(122)
plt.scatter(pca[:, 0], pca[:, 1], c=result)
plt.title(‘PCA’)
plt.colorbar()
plt.show()
对于高维度数据, 主函数中代码适当进行了改动, 只显示了最终的结果图。主函数部分代码如下:
if _name==’main‘:
epochs ( = 1000)
data,target=get_data()
perceptron=Perceptron(data.shape[1],f)
print(perceptron)
plot_result(perceptron,target)
for i in range(epochs):
perceptron.train(data, target)
if (i%400 = = 0) :
plot_result(perceptron, target)
print(perceptron)
acc ( = 0)
result=np.zeros_like(target) for i in range(data.shape[0]):
result[i]=perceptron.predict(data[i]) acc+=(result[i]==target[i]) plot_result(perceptron,target)
print(’acc={}’.format(acc / len(target)))
4 结果展示与分析
4.1 数据集一
首先使用第一个数据集进行展示, 在展示中, 为了更好的体现迭代过程中线性分界面的变化, 这里每隔 400 次展示一次结果, 效果如下图所示, 第一张为初始图, 分解面为初始化的值。
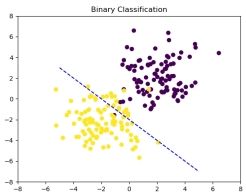
图 1: 初始
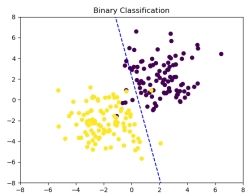
图 2: 迭代 400 次
可以看到迭代中分界面一直在进行变化来使得全部样本被正确划分, 但本数据集是线
性不可分的, 无法找到一条直线可以将所有样本都能正确被划分。
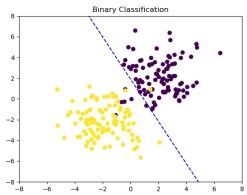
图 4: 最终结果
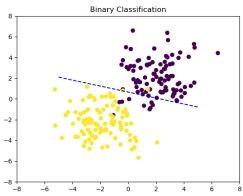
图 3: 迭代 800 次
经过了 1000 次的迭代后, 可以看到分界面几乎可以将绝大部分样本正确划分, 说明感知器模型较好的完成了线性分类的任务, 计算得到分类准确率为 0.965 , 印证了从图像中得到的结果。
在迭代的过程中,初始权值为 (\lbrack 1,1\rbrack) ,偏置为 2,经过 1000 次迭代后,weight ( = \lbrack {-} 0.10703409 {-} )
(0.05266879\rbrack,bias = 0.09999999999999931) 。
4.2 数据集二
与数据集一不同, 该数据集是线性可分的, 其他初始化参数部分基本与数据集一设置
相同。
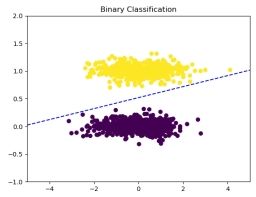
图 6: 迭代 400 次
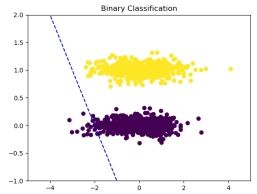
图 5: 初始
可以看到, 经过 400 次迭代后, 数据集已经可以完全正确的划分。
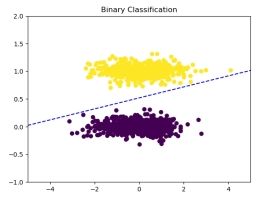
图 7: 迭代 800 次
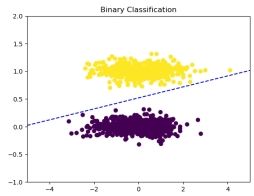
图 8: 最终结果
在迭代 400 次时, 就已经实现了正确的分类, 因此可以看到后来的迭代中, 线性分界
面并未发生改变, 因为在参数更新中, 无错误分类的样本, 因此权重并未被更新。
最后可以得到分类的准确率为 1.0, 效果很好, 初始化时, 参数为 weight ( = \left\lbrack 1.1\text{.} \right\rbrack,bias = )
2.0, 经过迭代后, weight ( = \lbrack{-}0.095474010.96129867\rbrack) ,bias ( = {-} 0.500000000000000000) 。
在这里, 我们可以发现一个现象, 线性分界面在完全将数据划分开后就不再改变, 因此分界面相对来说是有些 “偏” 的, 而不是像支持向量机那样, 达到距离最小化的效果, 这也反映了感知器的缺陷, 只是完成简单的分类, 并未考虑到样本整体的情况, 这样对于未知样本, 效果就会相对差一些。
4.3 数据集三
为了更好的展示迭代过程中准确率以及损失的变化, 确定足够迭代次数得到较好的结
果, 这里对这两项指标进行了记录, 结果如下图所示: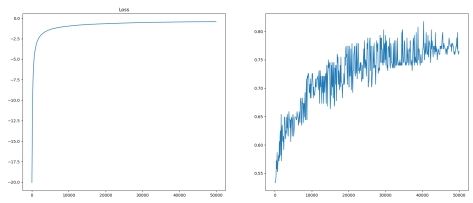
图 9: 损失准确率结果图
从上图可以看出, 随着迭代次数的增加, 损失不断减小, 因为是负数, 所以图中是不断
上升,一定次数后达到稳定,准确率不断上升,并达到约 (80%) 。
与前两个数据集不同, 第三个数据集维度较高, 无法用之前的方法进行可视化, 因此这里使用了两种方法 t-SNE 降维以及 PCA 降维, 从而对结果进行可视化, 结果如下图所示:
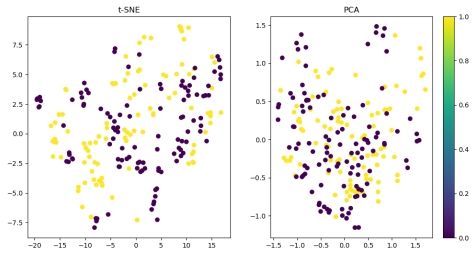
图 10: 降维结果图
降维效果不理想, 因此下文对其进行了探究。
在实验中发现, 由于数据维度过高, 1000 次迭代后, 数据仍未达到稳定的状态, 因此这里设置迭代次数为 50000 次, 由于数据维度过高, 不方便展示, 这里不再进行权重展示, 结果的准确率为 0.7836538461538461 , 也得到了较好的效果。
5 探究
降维效果并不理想, 这里存在疑问, 分类准确率较高的情况下, 降维效果不理想, 因此
这里又对 Sonar 数据集使用 K-means 聚类后降维展示, 结果如下:
从图中可以看出, 降维效果较好, 因此并不是数据集的问题。由于 kmeans 对此高维数据处理后, 降维效果很好, 可以说明并不是因为从维度高降到二维特征减少太多而无法表现良好的效果, 这里推测应该是对于感知器的分类结果并不能很好的降维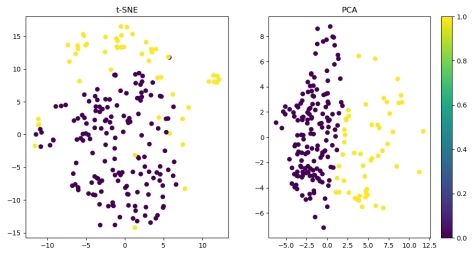
图 11: Sonar 使用 kmeans 降维结果图
6 总结
在本次实验中遇到了一些问题, 在此感谢尚荣华老师以及博士生的指导, 在感知器分
类的时候遇到了两个问题。
第一,对于数据高维度的 Sonar 数据集,为了可视化效果,这里使用了 (\mathrm{t} {-} \mathrm{SNE}) 以及 PCA 降维可视化, 但分类准确率高的同时, 降维效果并不好, 这里又对 Sonar 数据使用了聚类方法, 随后降维可视化, 其效果较好, 也对问题原因进行了推测。
第二, 对于高维数据的损失记录, 开始的记录为损失先迅速降低, 随后慢慢升高, 经过发现后发现记录损失的方式不对, 开始使用了每个样本标签与输出的插值的绝对值作为损失, 并求和, 这样是一中类似于均方误差的计算方式, 在高维超平面移动的过程, 这样的方式计算的并不是实际的损失, 因此查阅资料后使用了正确的损失函数计算, 结果较好。
本次实验中对感知器进行了实现, 并利用多种数据集进行展示, 得到了很好的效果, 在这次实验中, 开始在理解题意方面遇到了很多问题, 后来经过多方询问才明白。这次实验中我通过广泛查询资料了解到了相关的知识, 也认真写代码来完成任务, 这份作业的完成确实比较艰巨, 一份顶多份, 但是我还是有很大的收获, 能力也得到了提升。
A 程序代码
感知器实现程序 - 感知器.py
1 | # -*- coding:utf-8 -*- |
感知器实现 SONAR. 数据程序 - perceptron2.py
1 | # -*- coding:utf-8 -*- |




