
ActionFormer论文分享
ActionFormer论文分享
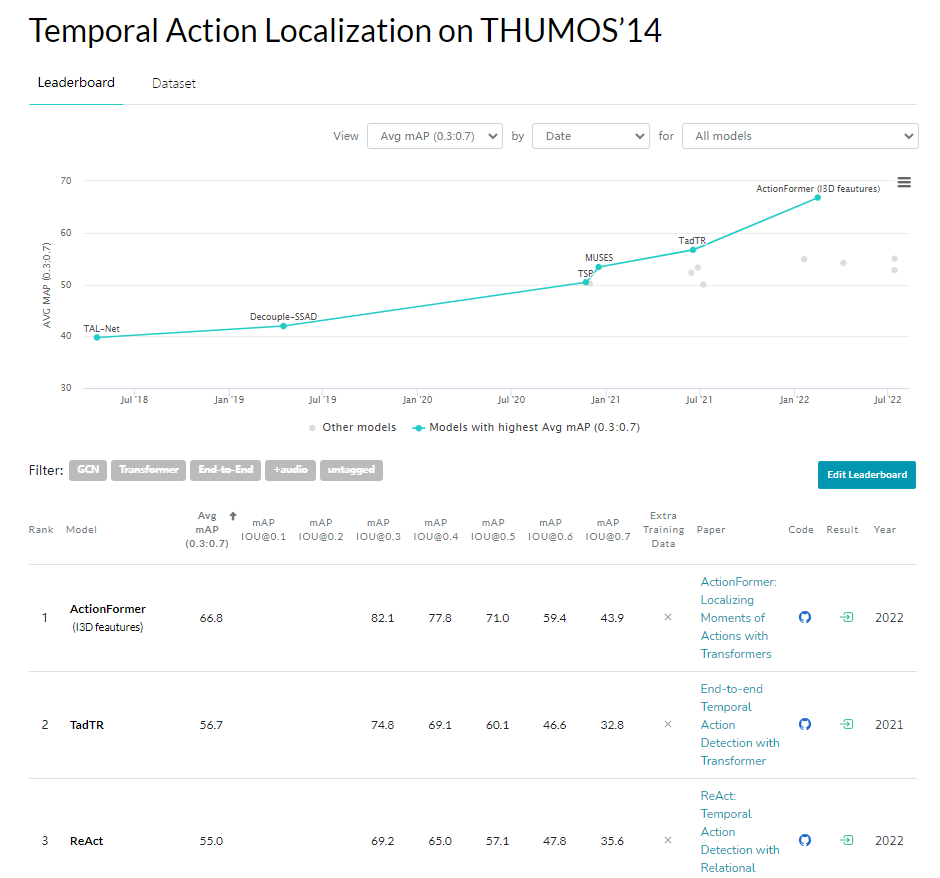
由于水平有限,讲的内容也可能会出现不是很正确的地方,欢迎大家批评指正,沟通交流。今天给大家分享的是之前做过的项目中使用到的一个模型,这个模型在时序定位中取得了非常好的效果,这是Papers with Code上在THUMOS14数据集上的结果,当后面几名还是相差一个点的时候,已经比第二名领先了十多个点,因此我拿来分享一下这个模型,讲一下关于模型的结构以及使用感受。
ActionFormer在THUMOS‘14效果
视频领域常用的数据集
**THUMOS14:**数据集包含大量的人类动作在真实环境中开源视频。 动作包括日常生活动作。THUMOS14的主要挑战是动作实例持续时间的巨大变化。具体来说,短动作实例只能持续十分之一秒,而长动作实例可以持续数百秒。
**ActivityNet :**是目前视频动作分析方向最大的数据集,包含分类和检测两个任务。目前的1.3版本有200个类别,涵盖了200种不同的日常活动。
**EPIC Kitchens 100:**记录了多个多角度、无脚本、本地环境中的厨房场景。它们均来自拍摄者真实的日常饮食生活,并且使用了一种新颖的实时音频评论方法来收集注释。
时序定位任务
动作识别可以看作是一个纯分类问题,其中要识别的视频基本上已经过剪辑,即每个视频包含一段明确的动作,视频时长较短,且有唯一确定的动作类别。而在时序动作定位领域,视频通常没有被剪辑,视频时长较长,动作通常只发生在视频中的一小段时间内,视频可能包含多个动作,也可能不包含动作,即为背景。找到视频中动作的起始和结束,很多时候还需要找出其中动作属于哪一类。这一任务类似于时间上的目标检测,因此很多目标检测中的方法也常常拿来应用在这一领域,比如Faster-RCNN中两阶段的思想,先找到候选区域,再筛选,回归修正。有基于滑窗的方法,基于候选区域的方法。而本次讲的ActionFormer则是单阶段无锚框的方法,如图中所示,直接通过Transformer模型预测出每一刻的动作类别和他们这一时间点到动作开始和结束的距离。
ActionFormer模型结构
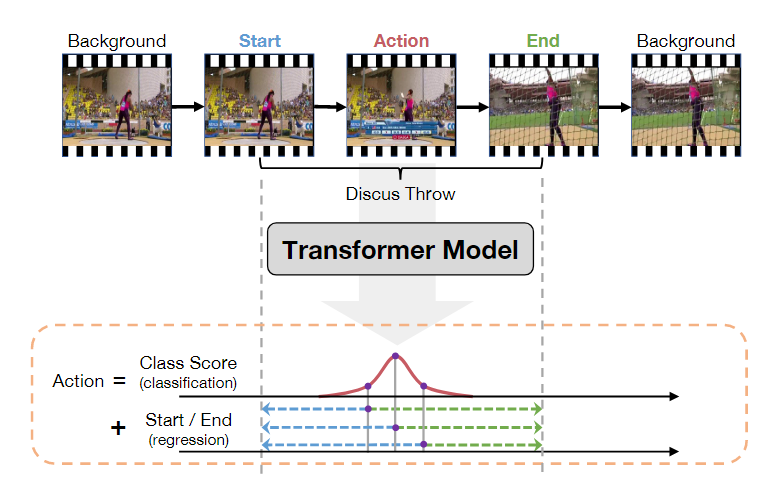
这一模型使用分类分数以及回归分数来计算出动作的情况,分类的分数用于对动作进行分类,回归的分数用于回归出动作的开始和结束的时间点,这个过程就有点像目标检测,事实上,时序定位的很多方法都是从目标检测中借鉴过来的,这里的分类和回归也就像目标检测中找到锚框中目标的类别和对锚框体的回归,不过时序定位的这个任务是在时间上一维的。
总体结构、输入输出
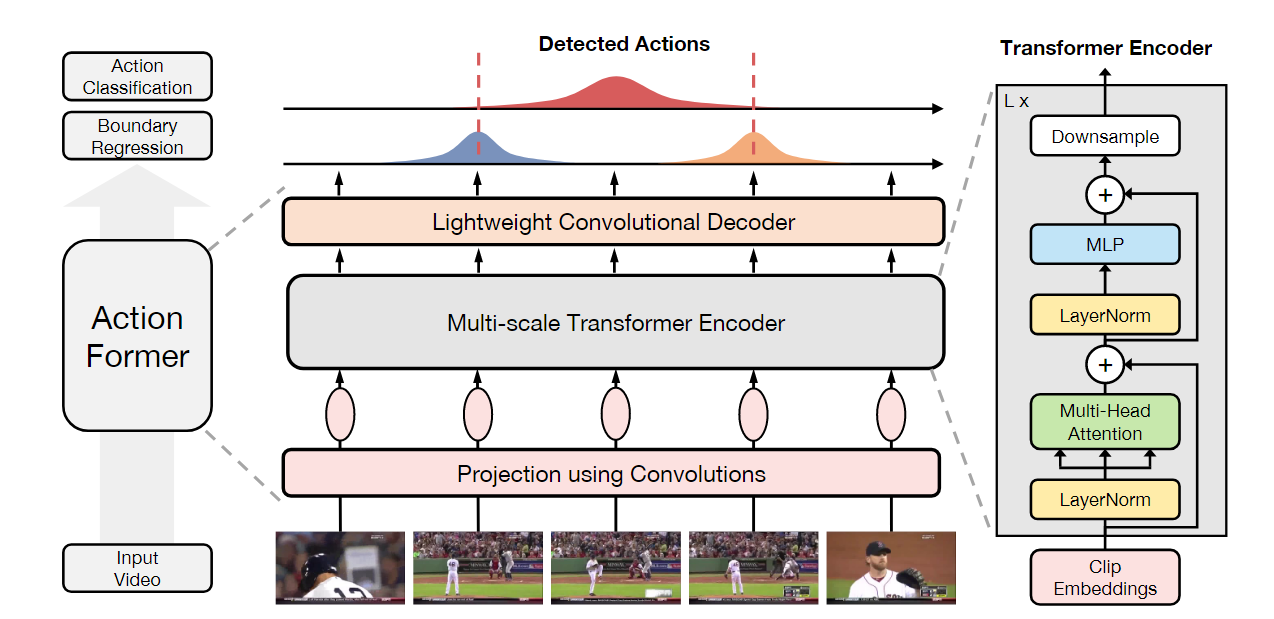
模型的输入是首先对视频经过特征提取,根据视频的长度处理成很多个向量,随后把特征向量送入网络,网络的开始是使用卷积进行映射,随后是一个Transformer结构作为编码器,经过这个结构之后,使用了一个轻量级的卷积进行解码,最后使用分类和回归头得到每个时刻的预测类别,开始和结束,最后通过转化变成预测的结果。
在送入模型训练的时候,只有特征向量是不行的,还是需要一些信息的,比如训练的时候就需要标注信息,片段的起始和末尾,所属的类型,划分为训练还是测试,视频的持续时间和fps帧率信息,在测试的时候不需要标注信息,但是关于视频的帧率和持续时间这些信息还是需要的。
对于模型的输出,我们需要的是一段时间的开始时刻,结束时刻以及对应的分类,因此问题可以转化为
对于时间上的每一个时刻,预测出$p(a_t),d^s_t,d^e_t$,其中$p(a_t)$包含C个值,随后使用以下的公式来求出该时刻预测的结果
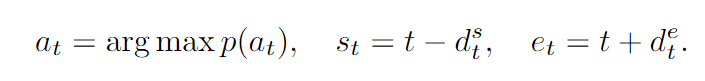
具体的结构可以划分为以下几个部分:
特征提取
使用卷积进行映射
Transformer编码器
卷积网络解码
分类和回归头
损失计算
接下来我讲详细讲这几个部分。
特征提取
特征提取是视频领域常用的操作,因为视频相比图片来说信息量更大,而且视频中存在着非常多的信息冗余,如果直接把视频放入网络,计算量也会很高,因此很多任务会使用特征提取后的特征进行处理。
使用预训练好的模型进行特征提取,一般常用双流I3D进行特征提取,双流I3D模型是视频领域中经典的模型,一路使用RGB信息建模空间信息,一路采用光流信息建模时间变化信息。预训练一般使用Kinetics-400这样的大型数据集,提取出1024*帧数的矩阵,向量和视频的帧具有时间上的对应关系,不过经过实验,其他模型如R(2+1)D、TSN等模型也可以,效果差不多。这里提取特征的时候,一般是采用一个特征向量对应16帧,然后每次向后移动1帧的这种形式,具体参数根据需要进行更改,这种得到的特征向量个数其实是总帧数-16,不过这点差别是不影响结果的。
用卷积进行映射
使用这一操作,论文中说有助于更好地结合时间序列数据的本地上下文,对于这一点,我的理解是卷积操作使得可以更好的捕捉到相邻时间前后的信息。
另一点是稳定视觉Transformer的训练,这一点怎么体现的具体论文也没说,我也不是很清楚。
多尺度Transformer进行编码
把$Z_0$进行特征表示,乘以一个W
$$
Q=Z^0W_Q, K=Z^0W_K, V=Z^0W_V
$$
自注意力输出,这里就是一般Transformer的这种方式,计算一个余弦相似度,然后进行缩放,进行softmax操作,最后和Value相乘得到结果。
$$
S=softmax(QK^T/\sqrt(D_q))V
$$
使用Transfomer的时候这里是通过使用可选的下采样构建特征池化金字塔,从而更好的关注到时间上不同距离的影响。
作者在后续的消融实验中证明了使用Transformer结构是取得好的效果最重要的原因。
在编码的时候作者也考虑使用位置编码,但是发现加上之后效果会更差,因此默认是没有使用的
使用卷积网络进行解码
对于使用卷积网络进行解码这一步骤中,这里使用的是带有分类和回归头的轻量级卷积网络。分类头检查特征金字塔上所有 L 层的每个时刻 t,并预测每个时刻 t 的动作概率 p(at)。分类网络是使用 3 层 1D 卷积实现的。回归头也检查金字塔上所有 L 级的每一时刻 t。不同之处在于,仅当当前时间步 t 位于某个动作中时,回归头才预测到动作开始和偏移的距离。除此之外,在后处理环节还使用了非极大值抑制(nms)操作,把多余的预测消除掉。
损失计算
在损失计算这部分,使用了分类损失和回归损失,仅当预测的分类不是背景的情况下计算回归损失,相应的还设置了权重。
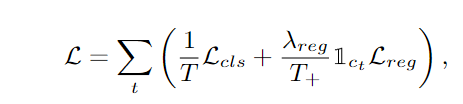
模型缺点与改进方向
缺点
最大的问题应该还是在于使用预提取的视频特征,不是端到端的模型,从实际使用来说,特征提取花的时间远大于实际的代码训练与推理,在项目应用中,一个几秒的视频特征提取在1060上需要6秒左右,而模型推理只需要0.02秒,这一问题在应用时感知非常明显。
另一问题应该还是使用了大量有标注的信息,而这一信息不易获取而且成本很高。
文中还提到了一个问题在于存在预定义动作词汇的约束。
改进方向
我觉得一个问题在于可以通过可学习的前处理操作替代特征提取的操作,特征提取这一步骤使用的预训练好的模型,在使用的时候是不计算梯度,更新参数的。最近我读了一篇视频领域标注的论文SWINBERT,感觉其中的思想可以参考一些,该模型的前面使用了Video Swin Transformer模型,后面使用了稀疏注意力,而且模型对于帧率是自适应的,不需要再指定视频的帧率信息,这一思路或许可以应用在这一领域。
另一个问题在于这种方法还是有监督学习,需要使用大量人工标记的视频样本进行学习还有预定义的动作词汇的约束,未来可以从预训练方面还有半监督无监督学习等方向改进,在没有人工标签的情况下从视频和文本语料库中学习。
还有一点作者认为目前还缺乏时序动作定位领域的预训练。目前在很多领域都有很大的数据集预训练,随后微调都能取得不错的效果,而在这一领域目前还缺乏。
使用感受
该模型不仅可以预测有开始和结束帧的情况,还可以把开始帧设为0,仅预测结束帧作为关键帧,经过实验发现这样的方法使用起来也没问题,也能取得很好的效果。
在项目中,使用该模型效果确实非常好,而且足够轻量级就可以完成一定要求的任务,训练推理都很快。
在不调参的情况下,使用其他数据集的参数配置效果就很好。
经过实验,在小规模数据集上表现良好。
额外增加了特征提取的操作,增加了使用的复杂度,使用起来需要组合,考虑更多的问题。
总而言之,这一模型在时序动作定位领域这一较为小众的方向中取得了不错的成绩,如果是相关方向的值得一看。




