
【论文阅读】 Deep High-Resolution Representation Learning for Visual Recognition
【论文阅读】 Deep High-Resolution Representation Learning for Visual Recognition
简介
在计算机视觉中高分辨的表示是非常重要的,HRNet是用于识别的高分辨网络,广泛的用于姿态检测以及语义分割中,也可用于目标检测。
网络结构
相比一般的网络,HRNet具有特殊的结构,一般的卷积神经网络往往是随着网络的深入,特征图的分辨率逐渐由高到低,这样的网络结构设计适合一般的视觉问题,视觉空间信息都是冗余的,对信息的精准度要求不高,但是这种结构在面对关键点检测以及语义分割问题的时候就不能很好的完成任务,精准度不够。因此就有了HRNet的结构设计如下图所示:
HRNet网络在模型的整个过程中都能保持高分辨率,采用并行的网络,不同的流的分辨率不同,在网络的第n个阶段有n流个网络,从前往后每次下采样一个流,同时在阶段的连接出对信息进行交汇,从高分辨率使用卷积到低分辨率,从低分辨率的流上采样到高分辨率的流,最终得到模型。
模型的特色有两点:
- 使用并行连接从高到低分辨率的卷积流
- 跨分辨率反复交换信息
使用并行连接使得在整个过程中都保持了高分辨率的表示,使用了跨分辨率的反复融合信息使得模型对于位置具有很强的敏感性,可以较好的完成相关的工作。
模型的变体
在HRNet模型中共提出了三种模型的结构,HRNetV1 HRNetV2以及HRNetV2p这三种结构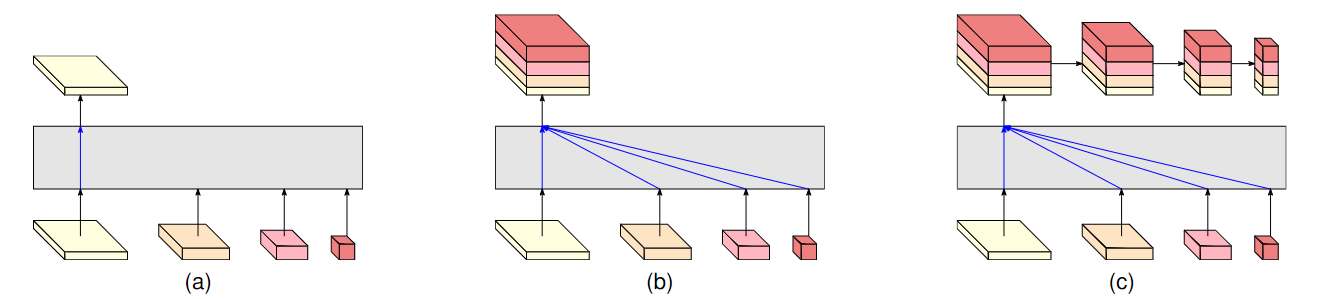
其中V1只使用了融合最后的高分辨率流,这种结构相比V2运算量更小,而在关键点检测任务中和V2版本性能基本没有差别。而V2版本对最后的信息都进行了融合,在语义分割任务中表现较好。V2p则是在V2的基础上形成特征金字塔,更适合目标检测任务。
消融实验
消融实验证明分辨率确实会影响关键的检测的质量,这一点与一般的感觉相符。对多分辨率融合的实验也证明了融合会带来好的性能提升。
结论
对该模型的研究中可以得到一个结论,针对特定的问题来设计网络架构可能是有用的。此外,一个可能的误解在于分辨率越高,HRNet的内存消耗越大,但是实际是在姿态估计、语义分割以及目标检测中,内存成本并未很高。





