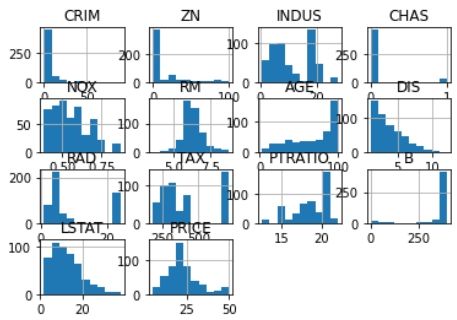
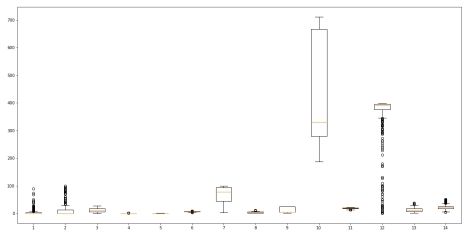
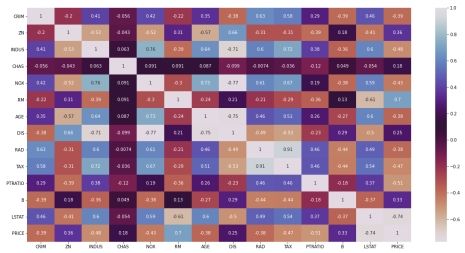
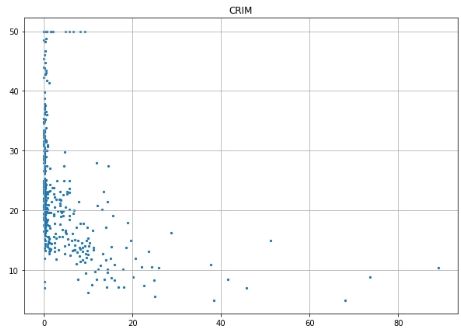
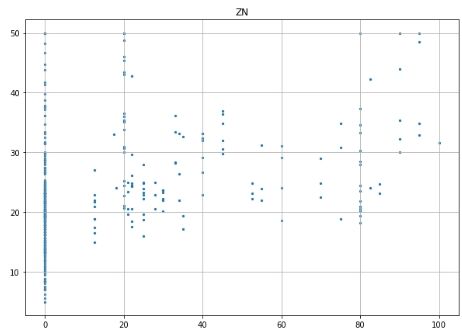
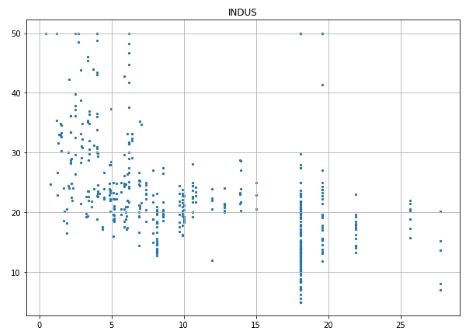
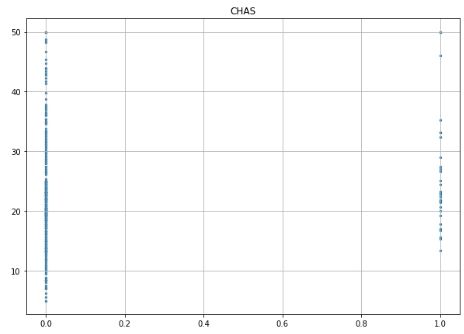
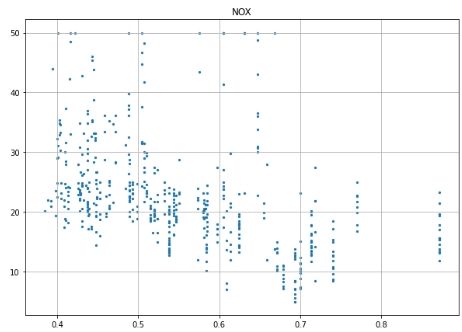
# Prepare data and labels for scatter plots data = np.array(all_data.iloc[:, :-1], dtype=float) label = np.array(all_data.iloc[:, -1], dtype=float)
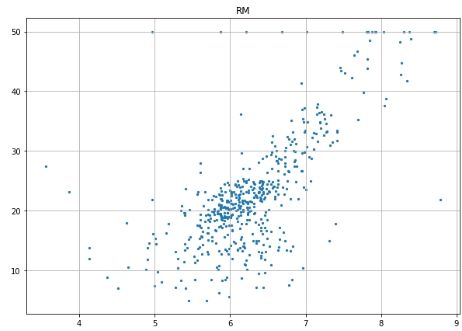
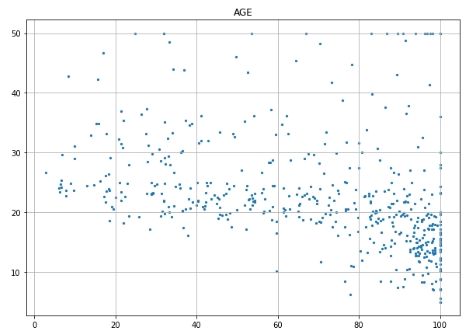
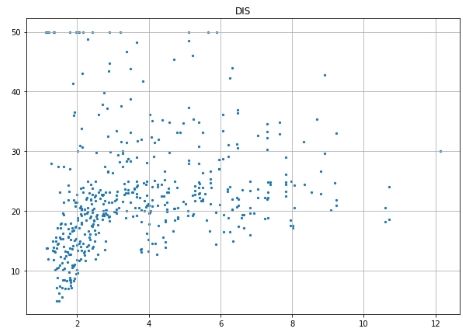
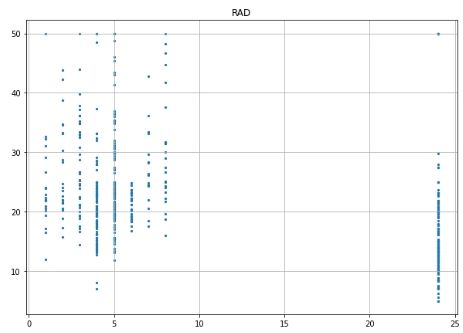
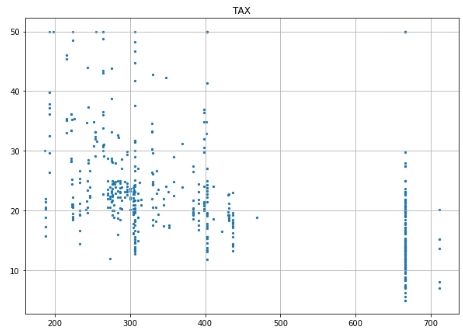
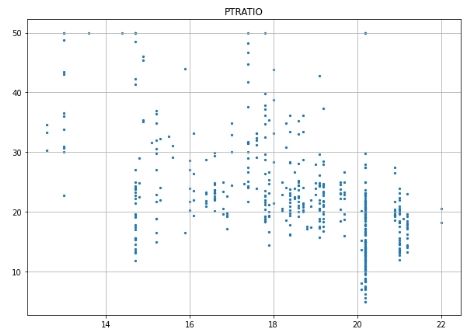
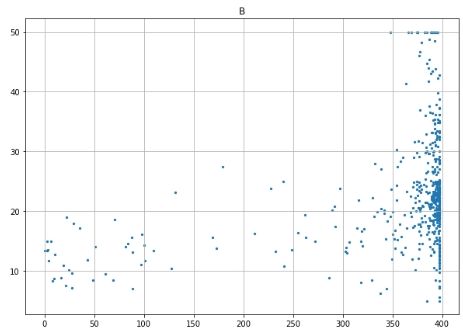
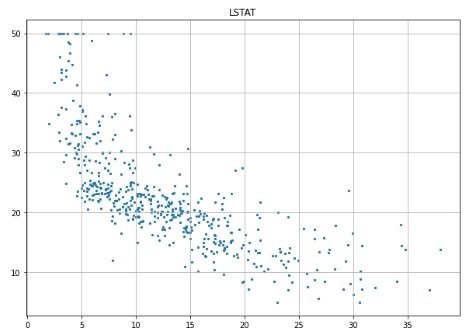
# Scatter plot for each feature for i inrange(13): plt.figure(figsize=(10, 7)) plt.grid() plt.scatter(data[:, i], label, s=5) # X, Y, point size plt.title(column_names[i]) plt.show()
# Remove less important features ('CHAS') unsF = [] # List to store indices of less important features for i inrange(data.shape[1]): if column_names[i] == 'CHAS': unsF.append(i)
data = np.delete(data, unsF, axis=1) # Remove less important feature
# Remove outliers in the target variable (PRICE > 46) unsT = [] # List to store indices of outliers for i inrange(label.shape[0]): if label[i] > 46: unsT.append(i)
data = np.delete(data, unsT, axis=0) # Remove samples with outlier prices label = np.delete(label, unsT, axis=0) # Remove outliers in labels
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, TensorDataset import torch.nn.functional as F import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.metrics import mean_squared_error, r2_score from sklearn.model_selection import train_test_split
# Convert data to tensors data = torch.tensor(data, dtype=torch.float) label = torch.tensor(label, dtype=torch.float)
# Split data into training and test sets X_train, X_test, y_train, y_test = train_test_split(data, label, test_size=0.3, random_state=4)
# Training function deftrain(model, device, train_loader, optimizer, epoch, criterion): model.train() loss = 0.0 for i, (data, target) inenumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = criterion(output, target.view_as(output)) loss.backward() optimizer.step() if i % 100 == 0: print('Train Epoch: {} Loss: {:.6f}'.format(epoch, loss.item() / len(train_loader)))
# Testing function deftest(model, device, test_loader, criterion): model.eval() test_loss = 0 with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) output = model(data) test_loss += criterion(output, target.view_as(output)).item() # Sum up batch loss test_loss /= len(test_loader.dataset) print('Test set: Average loss: {:.4f}\n'.format(test_loss)) return test_loss
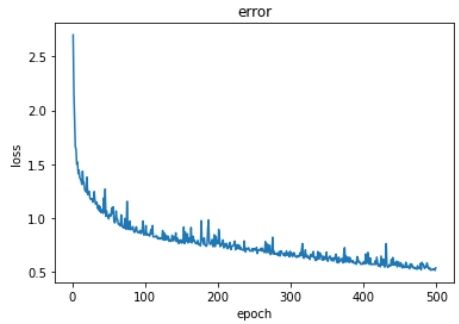
# Train and evaluate the model epoch_list, loss_list = [], [] for epoch inrange(1, 1000): train(model, device, trainloader, optimizer, epoch, criterion) test_loss = test(model, device, testloader, criterion) epoch_list.append(epoch) loss_list.append(test_loss)
# Plot the loss over epochs fig = plt.figure(figsize=(20, 10)) plt.plot(epoch_list, loss_list) plt.xlabel('epoch') plt.ylabel('loss') plt.title('Error') plt.show()
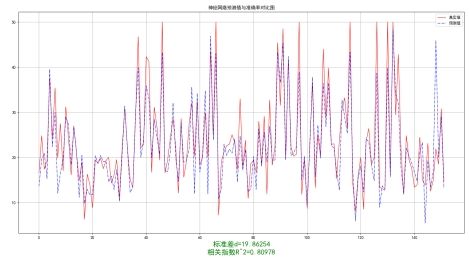
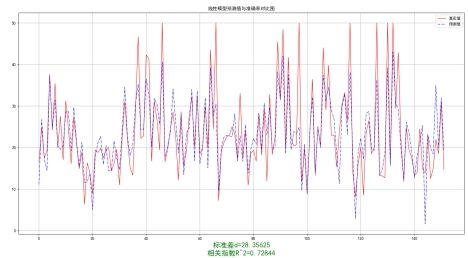
# Function to read and compare predicted and actual results defread(test_loader): model.eval() output_list, target_list = [], [] with torch.no_grad(): for data, target in test_loader: model.to('cpu') output = model(data).detach().cpu().numpy() output_list.extend(output) target_list.extend(target.cpu().numpy()) p = pd.DataFrame(output_list, columns=['predict']) p['real'] = target_list print(p.head()) return p
# Read predictions and calculate error p = read(testloader) error1 = mean_squared_error(p['real'], p['predict']).round(5) # Mean squared error score1 = r2_score(p['real'], p['predict']).round(5) # R^2 score
# Plot predictions vs actual values plt.rcParams['font.family'] = "sans-serif" plt.rcParams['font.sans-serif'] = "SimHei" plt.rcParams['axes.unicode_minus'] = False
import sklearn from sklearn import metrics from sklearn.model_selection import train_test_split import pandas as pd import numpy as np import torch import torch.nn as nn import torch.nn.functional as F from torch.utils.data import DataLoader from torch.utils.data import TensorDataset import matplotlib.pyplot as plt import seaborn as sns from skimage.metrics import mean_squared_error from sklearn.metrics import r2_score from sklearn.linear_model import LinearRegression